124
दृश्य

पिछला नवीनीकरण

नई वेबसाइट के मालिकों के लिए सबसे बड़ी गलतियों में से एक उनके robots.txt फ़ाइल में नहीं दिख रही है। तो यह वैसे भी क्या है, और इतना महत्वपूर्ण क्यों है? आपके जवाब हमारे पास हैं।
यदि आप एक वेबसाइट के मालिक हैं और अपनी साइट के एसईओ स्वास्थ्य के बारे में परवाह करते हैं, तो आपको अपने डोमेन पर robots.txt फ़ाइल से खुद को परिचित करना चाहिए। मानो या न मानो, कि एक अशांत उच्च संख्या वाले लोग हैं जो जल्दी से एक डोमेन लॉन्च करते हैं, एक त्वरित वर्डप्रेस वेबसाइट स्थापित करते हैं, और कभी भी अपने robots.txt फ़ाइल के साथ कुछ भी करने से परेशान नहीं होते हैं।
यह खतरनाक है। खराब तरीके से कॉन्फ़िगर किया गया robots.txt फ़ाइल वास्तव में आपकी साइट के एसईओ स्वास्थ्य को नष्ट कर सकती है, और आपके ट्रैफ़िक को बढ़ाने के लिए किसी भी संभावना को नुकसान पहुंचा सकती है।
robots.txt फ़ाइल को उपयुक्त नाम दिया गया है क्योंकि यह अनिवार्य रूप से एक फ़ाइल है जो वेब रोबोट (जैसे खोज इंजन रोबोट) के निर्देशों को सूचीबद्ध करती है कि वे आपकी वेबसाइट पर कैसे और क्या क्रॉल कर सकते हैं। यह 1994 के बाद से वेबसाइटों द्वारा एक वेब मानक है और सभी प्रमुख वेब क्रॉलर मानक का पालन करते हैं।
फ़ाइल आपकी वेबसाइट के रूट फ़ोल्डर में पाठ प्रारूप (एक .txt एक्सटेंशन के साथ) में संग्रहीत है। वास्तव में, आप किसी भी वेबसाइट के रोबोट को देख सकते हैं। एक्सट्रा फ़ाइल को केवल /robots.txt के बाद डोमेन टाइप करके देखें। यदि आप इसे groovyPost के साथ आज़माते हैं, तो आपको एक अच्छी तरह से संरचित किए गए रोबोट का एक उदाहरण दिखाई देगा।
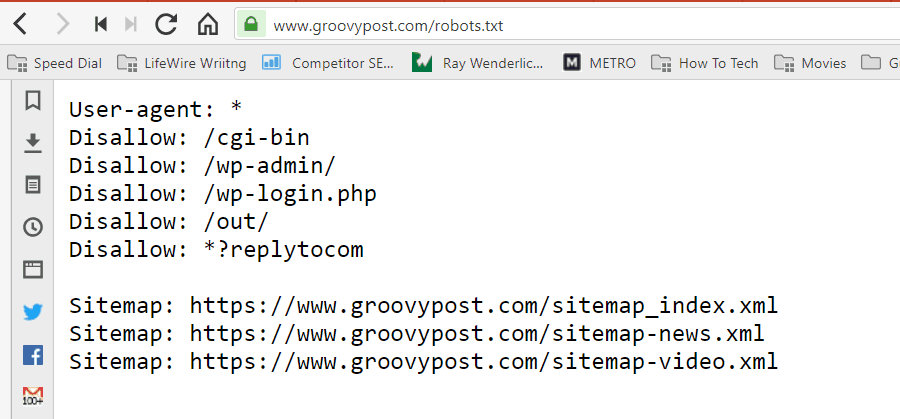
फ़ाइल सरल लेकिन प्रभावी है। यह उदाहरण फ़ाइल रोबोट के बीच अंतर नहीं करता है। का उपयोग करके सभी रोबोट को आदेश जारी किए जाते हैं उपभोक्ता अभिकर्ता: * निर्देश। इसका मतलब यह है कि इसके पालन करने वाले सभी कमांड उन सभी रोबोटों पर लागू होते हैं जो इसे क्रॉल करने के लिए साइट पर जाते हैं।
आप विशिष्ट वेब क्रॉलर के लिए विशिष्ट नियम भी निर्दिष्ट कर सकते हैं। उदाहरण के लिए, आप Googlebot (Google के वेब क्रॉलर) को अपनी साइट पर सभी लेखों को क्रॉल करने की अनुमति दे सकते हैं, लेकिन आप चाहते हो सकते हैं आपकी साइट पर रेंगने वाले लेखों से रूसी वेब क्रॉलर यांडेक्स बॉट को हटा दें, जिनके बारे में असंगत जानकारी है रूस।
ऐसे सैकड़ों वेब क्रॉलर हैं जो वेबसाइटों के बारे में जानकारी के लिए इंटरनेट को कुरेदते हैं, लेकिन जिन 10 सबसे आमों के बारे में आपको चिंतित होना चाहिए, वे यहां सूचीबद्ध हैं।
ऊपर के उदाहरण परिदृश्य को लेते हुए, यदि आप Googlebot को अपनी साइट पर सब कुछ अनुक्रमित करने की अनुमति देना चाहते थे, लेकिन चाहते थे अपने रूसी आधारित लेख सामग्री को अनुक्रमित करने से यांडेक्स को ब्लॉक करें, आप अपने robots.txt में निम्न पंक्तियाँ जोड़ेंगे फ़ाइल।
उपयोगकर्ता-एजेंट: googlebot
अस्वीकार करें: अस्वीकृत करें: / wp-admin /
अस्वीकार करें: /wp-login.php
उपयोगकर्ता-एजेंट: yandexbot
अस्वीकार करें: अस्वीकृत करें: / wp-admin /
अस्वीकार करें: /wp-login.php
अस्वीकार करें: / रसिया /
जैसा कि आप देख सकते हैं, पहला खंड केवल Google को आपके वर्डप्रेस लॉगिन पृष्ठ और प्रशासनिक पृष्ठों को क्रॉल करने से रोकता है। दूसरा खंड यैंडेक्स को उसी से रोकता है, लेकिन आपकी साइट के उस पूरे क्षेत्र से भी, जहाँ से आपने रूस विरोधी सामग्री वाले लेख प्रकाशित किए हैं।
यह एक सरल उदाहरण है कि आप कैसे उपयोग कर सकते हैं अनुमति न दें आपकी वेबसाइट पर आने वाले विशिष्ट वेब क्रॉलर को नियंत्रित करने के लिए कमांड।
केवल वही आदेश न दें जिसके पास आपकी robots.txt फ़ाइल में पहुंच है। आप किसी भी अन्य कमांड का उपयोग कर सकते हैं जो यह निर्देशित करेगा कि कोई रोबोट आपकी साइट को कैसे क्रॉल कर सकता है।
ध्यान रखें कि बॉट्स करेंगे केवल जब आप बॉट का नाम निर्दिष्ट करते हैं तो आप जो आदेश देते हैं, उसे सुनें।
एक आम गलती जो लोग करते हैं, वे सभी bots से / wp-admin / जैसे क्षेत्रों को अस्वीकार कर रहे हैं, लेकिन फिर एक googlebot अनुभाग निर्दिष्ट करते हैं और केवल अन्य क्षेत्रों (जैसे / के बारे में /) को अस्वीकार कर रहे हैं।
चूंकि बॉट केवल आपके अनुभाग में आपके द्वारा निर्दिष्ट आदेशों का पालन करते हैं, इसलिए आपको उन सभी आदेशों को पुनर्स्थापित करने की आवश्यकता होती है जिन्हें आपने सभी बॉट्स के लिए निर्दिष्ट किया है (* उपयोगकर्ता-एजेंट का उपयोग करके)।
ध्यान रखें कि robots.txt वैध बॉट्स (जैसे खोज इंजन बॉट) को आपकी साइट को अधिक प्रभावी ढंग से क्रॉल करने में मदद करने के लिए है।
वहाँ बहुत से विक्षिप्त क्रॉलर हैं जो आपकी साइट को रेंगने जैसे ईमेल पते जैसे काम करते हैं या आपकी सामग्री चुराते हैं। अगर आप उन क्रॉलर को अपनी साइट पर कुछ भी क्रॉल करने से रोकने के लिए अपनी robots.txt फ़ाइल का उपयोग करना चाहते हैं, तो परेशान न हों। उन क्रॉलर के निर्माता आमतौर पर आपके द्वारा बनाई गई किसी भी चीज़ को अनदेखा कर देते हैं, जिसे आप अपने robots.txt फ़ाइल में डालते हैं।
आपकी वेबसाइट पर यथासंभव गुणवत्ता सामग्री क्रॉल करने के लिए Google का खोज इंजन प्राप्त करना अधिकांश वेबसाइट मालिकों के लिए प्राथमिक चिंता का विषय है।
हालाँकि, Google केवल एक सीमित खर्च करता है क्रॉल बजट तथा क्रॉल दर व्यक्तिगत साइटों पर। क्रॉल दर, क्रॉलिंग ईवेंट के दौरान आपकी साइट पर Googlebot प्रति सेकंड कितने अनुरोध करेगा।
अधिक महत्वपूर्ण क्रॉल बजट है, जो कि Googlebot को एक सत्र में आपकी साइट को क्रॉल करने के लिए कुल कितने अनुरोध करेगा। Google आपकी साइट के क्षेत्रों पर ध्यान केंद्रित करके अपना क्रॉल बजट खर्च करता है जो हाल ही में बहुत लोकप्रिय हैं या बदल गए हैं।
आप इस जानकारी के लिए अंधे नहीं हैं। अगर आप जाएँ Google वेबमास्टर उपकरण, आप देख सकते हैं कि क्रॉलर आपकी साइट को कैसे संभाल रहा है।
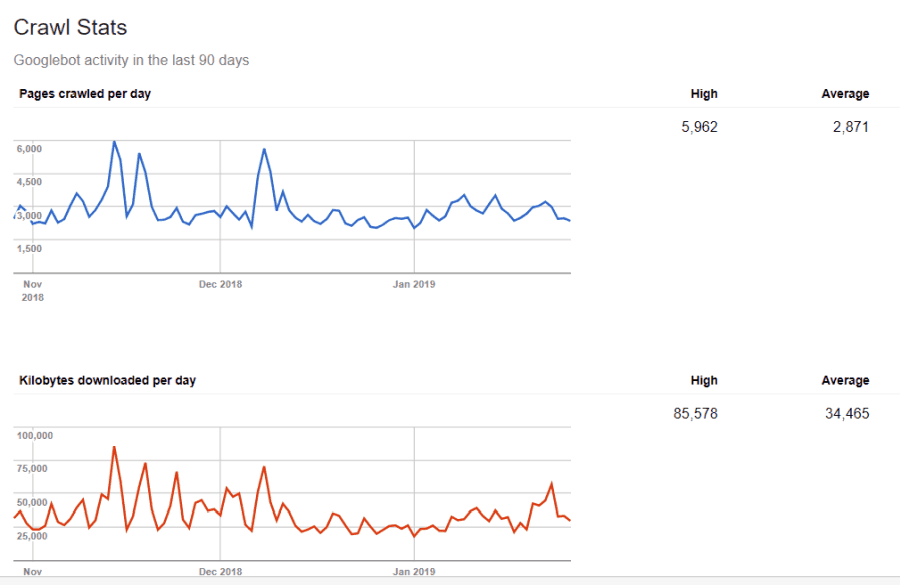
जैसा कि आप देख सकते हैं, क्रॉलर हर दिन आपकी साइट पर इसकी गतिविधियों को बहुत स्थिर रखता है। यह सभी साइटों को क्रॉल नहीं करता है, लेकिन केवल वे ही इसे सबसे महत्वपूर्ण मानते हैं।
अपनी साइट पर क्या महत्वपूर्ण है, यह तय करने के लिए Googlebot को क्यों छोड़ें, जब आप अपनी robots.txt फ़ाइल का उपयोग करके यह बता सकते हैं कि सबसे महत्वपूर्ण पृष्ठ क्या हैं? यह Googlebot को आपकी साइट पर कम-मूल्य वाले पृष्ठों पर समय बर्बाद करने से रोकेगा।
Google वेबमास्टर टूल आपको यह भी जांचने देता है कि क्या Googlebot आपकी robots.txt फ़ाइल को ठीक से पढ़ रहा है या नहीं और कोई त्रुटि है या नहीं।
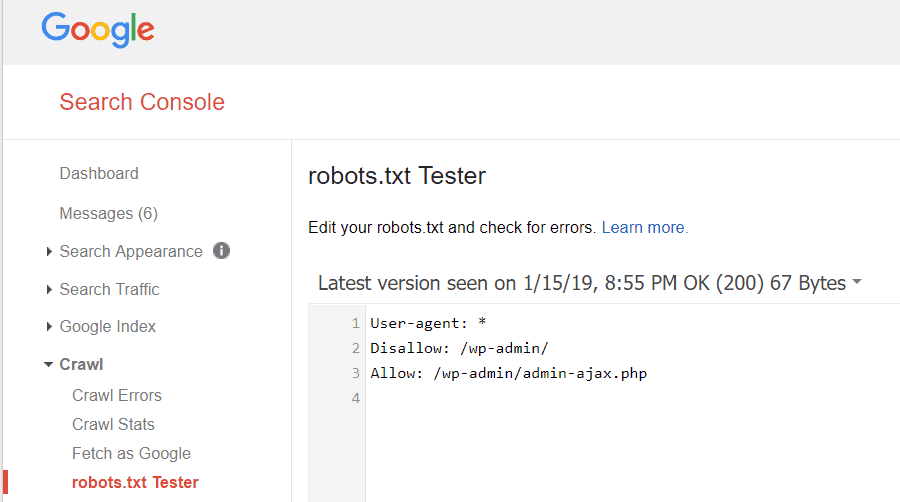
इससे आपको यह सत्यापित करने में मदद मिलती है कि आपने अपनी robots.txt फ़ाइल को सही ढंग से संरचित किया है।
आपको Googlebot से किन पृष्ठों को अस्वीकृत करना चाहिए? निम्न पृष्ठों की श्रेणियों को अस्वीकार करने के लिए आपकी साइट एसईओ के लिए यह अच्छा है।
नई वेबसाइट मालिकों द्वारा की गई सबसे बड़ी गलती कभी भी उनके robots.txt फ़ाइल को नहीं देख रही है। सबसे खराब स्थिति यह हो सकती है कि robots.txt फ़ाइल वास्तव में आपकी साइट, या आपकी साइट के क्षेत्रों को क्रॉल होने से रोक रही है।
अपनी robots.txt फ़ाइल की समीक्षा करना सुनिश्चित करें और इसे अनुकूलित करना सुनिश्चित करें। इस तरह, Google और अन्य महत्वपूर्ण खोज इंजन आपकी वेबसाइट के साथ दुनिया को पेश करने वाली सभी शानदार चीजों को "देखते हैं"।