0
दृश्य


पिछला नवीनीकरण

वेबैक मशीन सबसे लोकप्रिय हिस्सा है इंटरनेट आर्काइव वेबसाइट. पहली बार 2001 में शुरू किया गया, मुफ्त ऑनलाइन टूल आपको "समय में वापस" जाने देता है यह देखने के लिए कि दुनिया भर की वेबसाइटें किस समय बिंदुओं पर दिखती थीं। वेबैक मशीन में 562 सुविधाएँ हैं एक अरब इस लेखन के समय वेब पेज, हर साल कई और जोड़े गए।
यहां वेबैक मशीन पर एक नज़र है और जो इसे खास बनाती है।
ब्रूस्टर काहले और ब्रूस गिलियाट द्वारा निर्मित, इंटरनेट आर्काइव एक गैर-लाभकारी संगठन है, जिसके पास "सभी ज्ञान तक सार्वभौमिक पहुंच" के एक कथित मिशन के साथ है। शुरू से, संगठन ने डिजिटल सामग्री जैसे वेब पेज, किताबें, ऑडियो रिकॉर्डिंग, लाइव कॉन्सर्ट, वीडियो, चित्र और सॉफ्टवेयर सहित मुफ्त सार्वजनिक पहुंच प्रदान की है। कार्यक्रम।
आज तक, इंटरनेट आर्काइव द्वारा एकत्र की गई हर चीज में 70 से अधिक का समय लगता है पेटाबाइट सर्वर स्पेस की, जिसमें हर चीज की दो प्रतियां शामिल हैं। संगठन को पुस्तक डिजिटलीकरण सेवाओं से दान, अनुदान और शुल्क के माध्यम से वित्त पोषित किया जाता है। गोपनीयता के लिए, इंटरनेट आर्काइव अपने पाठकों के आईपी पते पर नज़र नहीं रखता है और पूरे HTTPS (सुरक्षित) प्रोटोकॉल का उपयोग करता है।
इंटरनेट आर्काइव का सिर्फ एक हिस्सा, वेकबैक मशीन, वेबसाइट की सामग्री को पकड़ने के लिए डिज़ाइन किया गया था जो बदल गया है या हटा दिया गया है। लॉन्च होने के बाद से, यह वेब पर सबसे लोकप्रिय और मान्यता प्राप्त स्थानों में से एक बन गया है। 1960 के दशक की एनिमेटेड सीरीज़, द रॉकी और बुलविंकल शो में काल्पनिक समय-यात्रा करने वाले उपकरण के बाद काहले और गिलियाट ने इस साइट का नाम रखा।
हालांकि इंटरनेट आर्काइव ने अक्टूबर 2001 तक इस साइट को जनता के लिए लॉन्च नहीं किया, लेकिन वेबैक मशीन ने मई 1996 से शुरू होने वाले कैश्ड वेब पेजों को संग्रहित करना शुरू कर दिया। 2001 तक, डिजिटल टेपों ने उन सूचनाओं को संग्रहीत किया जो केवल वैज्ञानिकों और शोधकर्ताओं का चयन करने के लिए सुलभ थे। जब पांच साल बाद सब कुछ जनता के सामने आया (जैसा कि लंबे समय से योजनाबद्ध था), इसमें पहले से ही 10 बिलियन से अधिक संग्रहीत पृष्ठ शामिल थे।
आज, साइट लिनक्स नोड्स के क्लस्टर पर ऐतिहासिक वेब डेटा रखती है। वेबैक मशीन अपने क्रॉल तंत्र के माध्यम से वेब पेजों पर सभी सार्वजनिक रूप से सुलभ जानकारी और डेटा फ़ाइलों को डाउनलोड करती है। हालाँकि, वेबसाइट पर पोस्ट की गई हर चीज़ को यहाँ शामिल नहीं किया गया है क्योंकि कुछ सामग्री प्रतिबंधित है या डेटाबेस में संग्रहीत है, जो सुलभ नहीं है। इस वजह से, कुछ वेबसाइटों को दूसरों की तुलना में बेहतर क्रॉल किया जाता है, यह इस बात पर निर्भर करता है कि डेवलपर्स ने एक समय में एक साइट कैसे बनाई।
आप नए संग्रह को भी देखेंगे, जो किसी भी साइट के लिए अधिक सामग्री उपलब्ध होगी। 2005 में पेश किया गया एक नया टूल इंटरनेट आर्काइव एक कारण है कि नया डेटा अधिक पूर्ण है। Archive-It.org आंशिक रूप से कैश की गई वेबसाइटों में विसंगतियों को दूर करने में मदद करता है ताकि संस्थानों और सामग्री रचनाकारों को डिजिटल सामग्री के संग्रह की कटाई और संरक्षण करने की अनुमति मिल सके।
वेब क्रॉलर, जिसे कभी-कभी मकड़ी या मकड़ी का जाला भी कहा जाता है, इंटरनेट जितना ही पुराना होता है। ये क्रॉलर इंटरनेट बॉट हैं जो लगातार अनुक्रमित उद्देश्यों के लिए वेब ब्राउज़ करते हैं, जिससे वे किसी भी आधुनिक खोज इंजन का एक महत्वपूर्ण घटक बन जाते हैं। वेबसाइटों के डिजिटल स्नैपशॉट बनाने के लिए वेबैक मशीन के लिए उपयोग किए जाने वाले क्रॉलर विभिन्न स्रोतों से आते हैं, जो समय के साथ बदल गए हैं।
जैसा कि आप जल्दी से नोटिस करते हैं, स्नैपशॉट कैप्चर की आवृत्ति वेबसाइट द्वारा बहुत भिन्न होती है। आमतौर पर, एक वेबसाइट जितनी बड़ी (और शायद अधिक लोकप्रिय) होती है, उतनी ही रेंगने वाली भी होती है। इसके अलावा, बहुत कुछ इस बात पर निर्भर करता है कि किसी वेबसाइट में कितनी बार पृष्ठ परिवर्तन होते हैं। यहां तक कि छोटी वेबसाइटों को भी तब तक क्रॉल किया जाता है जब तक कि कोई कारण न हो। उदाहरण के लिए, पासवर्ड-सुरक्षित साइटें क्रॉल नहीं की जाती हैं, और न ही ऐसी वेबसाइटें हैं जिनके साइट मालिकों ने अनुरोध किया है कि उन्हें शामिल नहीं किया जाए।
Wayback Machine वेबसाइट किसी के लिए भी उपयोग करना आसान है। किसी वेबसाइट के ऐतिहासिक स्नैपशॉट खोजने के लिए, उसका नाम साइट के खोज इंजन में टाइप करें। खोज परिणाम पृष्ठ पर, हाइपरलिंक्स तारीखों को निरूपित करते हैं और एक साइट को संग्रहीत किया गया था। "समय में वापस" साइट देखने के लिए लिंक पर क्लिक करें।
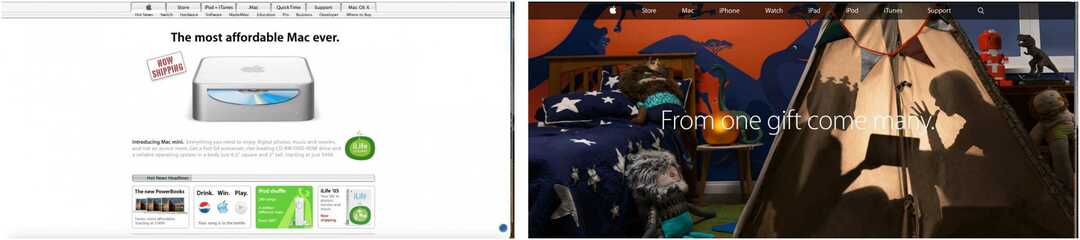
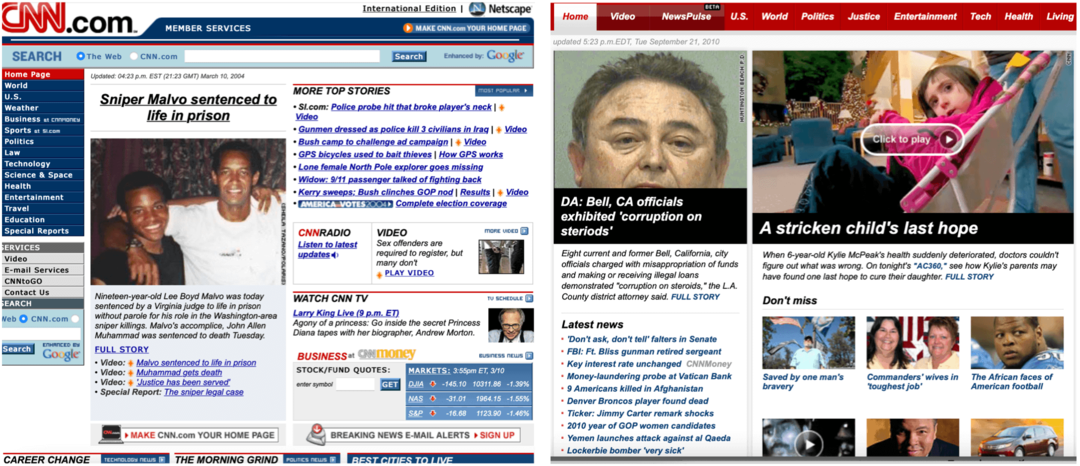
निम्नलिखित उदाहरणों में, आप फरवरी 2005 और नवंबर 2014 में दर्ज की गई Apple वेबसाइट के फ्रंट पेज और मार्च 2004 और सितंबर 2010 की तारीख से CNN होमपेज देख सकते हैं।
नोट: इन क्रॉलों में अन्य पृष्ठों के लिंक भी शामिल हैं, जो दिए गए तारीखों में दर्ज किए गए हैं, न कि केवल घरेलू पृष्ठों पर।
शोधकर्ताओं और सार्वजनिक रूप से एक जैसे के लिए बनाया गया, वेबैक मशीन में कुछ अंतर्निहित उपकरण हैं जो आकस्मिक उपयोगकर्ताओं को याद आ सकते हैं। उदाहरण के लिए, डिजाइन के आधार पर, खोज परिणाम पृष्ठ संदर्भ के लिए आसान होते हैं। जैसा कि समझाया गया है, “यदि आपको एक संग्रहीत पृष्ठ मिलता है जिसे आप अपने वेब पेज पर या किसी लेख में संदर्भित करना चाहते हैं, तो आप URL की प्रतिलिपि बना सकते हैं। तुम भी फजी यूआरएल मिलान और तारीख विनिर्देश का उपयोग कर सकते हैं... लेकिन यह थोड़ा और अधिक उन्नत है। "
वेबैक मशीन साइट मालिकों को एक विशिष्ट पृष्ठ को बचाने के लिए "सेव पेज नाउ" सुविधा का उपयोग करने की अनुमति देती है। और फिर भी, यह सही नहीं है। वर्तमान में, सुविधा साइट URL को भविष्य के किसी भी क्रॉल में नहीं जोड़ती है। इसके अतिरिक्त, अनुरोध एक से अधिक पृष्ठ सहेजता नहीं है। हालाँकि, ऐतिहासिक रिकॉर्ड के लिए अपनी वेबसाइट के मुखपृष्ठ को संग्रहीत करना एक अच्छा पहला कदम है।
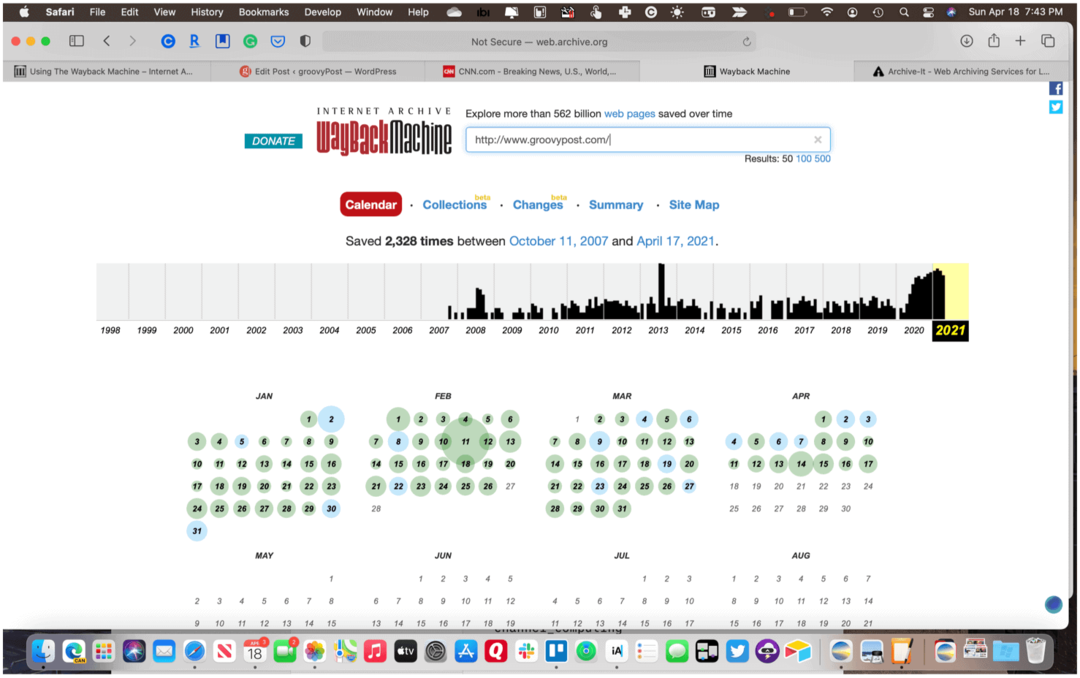
नई खोज करने के लिए आपको हर बार वेकबैक मशीन पर नहीं जाना होगा। इसके बजाय, आप अपने वेब ब्राउज़र टूलबार में पता लिखकर सामग्री पा सकते हैं। सभी खोजों के लिए इस प्रारूप का उपयोग करें: http://web.archive.org/*/www.yoursite.com/*. उदाहरण के लिए, का उपयोग करें http://web.archive.org/*/www.groovypost.com/* GroovyPost के लिए संग्रहीत पृष्ठों को खोजने के लिए!
अंत में, वेबैक मशीन केवल वेब के माध्यम से स्थित नहीं है। आप के लिए एक Wayback मशीन एप्लिकेशन पा सकते हैं आईओएस तथा एंड्रॉयड. क्रोम, सफारी और फ़ायरफ़ॉक्स के लिए एक्सटेंशन भी हैं। डेवलपर्स इंटरनेट आर्काइव वेबैक मशीन एपीआई की भी जांच करना चाहेंगे। ये डेवलपर्स के लिए वेबैक कैप्चर डेटा के बारे में जानकारी प्राप्त करना आसान बनाते हैं।
इंटरनेट आर्काइव वेबैक मशीन कई अलग-अलग एपीआई का समर्थन करती है। ऐसा करने से, डेवलपर्स के लिए वेबैक कैप्चर डेटा के बारे में जानकारी प्राप्त करना आसान हो जाता है।
अपनी पसंदीदा वेबसाइटों के लिए "बैक इन टाइम" जाना, वेबैक मशीन पर जाने का नंबर 1 कारण है। यह स्कूल परियोजनाओं या व्यावसायिक उपयोग के लिए वेबसाइट के इतिहास पर शोध करने वाले किसी भी व्यक्ति के लिए एक महान उपकरण है। आप जो भी करते हैं, वेबैक मशीन पर जाएं और देखें कि आप कुछ सरल चरणों में क्या खोज सकते हैं।
इंटरनेट संग्रह पुरालेख-इट सदस्यता सेवा के बारे में अधिक जानकारी के लिए, पर जाएँ आधिकारिक वेबसाइट और आज योगदान देना शुरू करें!

